Imagine speaking a few simple sentences into a microphone, and moments later, hearing those words read back through AI voice cloning with your unique timbre, accent, and vocal quirks in text you've never seen before. This isn't science fiction; it's the reality of what artificial intelligence voice cloning technology can achieve. By leveraging sophisticated neural networks and deep learning algorithms, AI voice cloning has evolved from initial curiosity to powerful tool, enabling machines to capture and reproduce the distinctive characteristics of human speech with astonishing precision.
In the past decade, this technology has transformed from producing obviously mechanical utterances to generating sounds almost indistinguishable from authentic human recordings. As voice cloning capabilities advance rapidly, industries from entertainment and localization to accessibility and customer service are undergoing fundamental transformation—while simultaneously raising profound questions about identity, consent, and the very nature of what makes a voice "real." Now, let's examine how AI voice cloning technology has progressively navigated technological turning points, merged with extraordinary human creativity, and the serious ethical challenges it faces.

What Was the Early Form of AI Voice Cloning?
The journey of AI voice cloning began in the early 1990s, marking the first steps toward what would eventually revolutionize how we interact with technology. The initial iterations of AI voice cloning were remarkably primitive compared to today's standards. These early systems primarily relied on rule-based algorithms, concatenative synthesis, and formant synthesis techniques to produce basic text-to-speech (TTS) output.
In its embryonic stage, AI voice cloning could only generate mechanical and monotonous speech patterns that lacked natural intonation and emotional expression. The technology was essentially focused on converting written text into audible speech rather than replicating specific human voices with their unique characteristics. Early representative technologies included concatenative synthesis systems developed by institutions like UC Berkeley, which worked by stitching together pre-recorded speech segments to form complete sentences. However, these systems were severely limited by their recording libraries, making it impossible to generate truly new voices.
Limitations That Hindered Progress
The constraints of early AI voice cloning were substantial:
- The synthesized voices sounded robotic and lacked emotional range
- There was minimal capability for voice personalization
- The technology had limited ability to capture vocal nuances
- True "cloning" of a specific individual's voice was not yet possible
These limitations created a wide gap between synthetic speech and authentic human vocalization, making AI-generated voices immediately recognizable as artificial. How could this technology evolve to cross the uncanny valley? The answer would come through several revolutionary breakthroughs in the following decades.
Critical Turning Points in AI Voice Cloning Development
The evolution of AI voice cloning reached several pivotal moments that dramatically transformed its capabilities and applications. Perhaps the most significant breakthrough came in 2016 when DeepMind introduced WaveNet, a deep neural network designed to generate audio waveforms directly. This innovation marked a paradigm shift from traditional concatenative synthesis methods, substantially enhancing the natural quality and detail of synthesized speech.
Another transformative advancement appeared with Baidu's Deep Voice system, which pioneered end-to-end neural networks for voice synthesis. This approach streamlined the training process and reduced dependence on extensive pre-recorded audio data, improving both efficiency and scalability. The development of few-shot learning models like SV2TTS further democratized voice cloning by enabling the technology to replicate voices using just minutes of sample audio, dramatically lowering the entry barrier.
How Commercial Applications Accelerated Progress
The commercialization of AI voice cloning technology through companies like Resemble AI brought these advancements to wider audiences. These enterprises introduced products supporting real-time adjustment of pitch, emotion, and multilingual cloning, expanding potential use cases across industries. Each of these turning points addressed specific limitations of earlier systems, gradually building the foundation for today's sophisticated voice cloning technology.
Despite these remarkable advancements, significant hurdles remained:
- Systems required large volumes of high-quality audio recordings (several hours)
- Training costs remained prohibitively expensive for many applications
- Generated speech still lacked emotional variability, retaining a mechanical quality
- Support was limited to single languages, with processing times ranging from minutes to hours
These challenges would drive the next wave of innovation in the field, pushing researchers and companies to develop increasingly sophisticated approaches to instant AI voice cloning.
Current State of AI Voice Cloning Technology
Today's AI voice cloning landscape has evolved dramatically, employing cutting-edge technologies that were unimaginable just a few years ago. Modern systems leverage sophisticated deep learning models including WaveNet, Tacotron, FastSpeech, Microsoft's VALL-E, and DINO-VITS, combined with neural vocoders and encoders to achieve high-fidelity speech synthesis with rich emotional expression.
The capabilities of current AI voice cloning technology are truly remarkable. Systems now support cloning from extremely short audio samples (as little as 3 seconds), real-time speech generation, emotion and speed modulation, multilingual and dialect support, and even zero-shot expression transfer. These advances have transformed what's possible in the voice cloning domain.
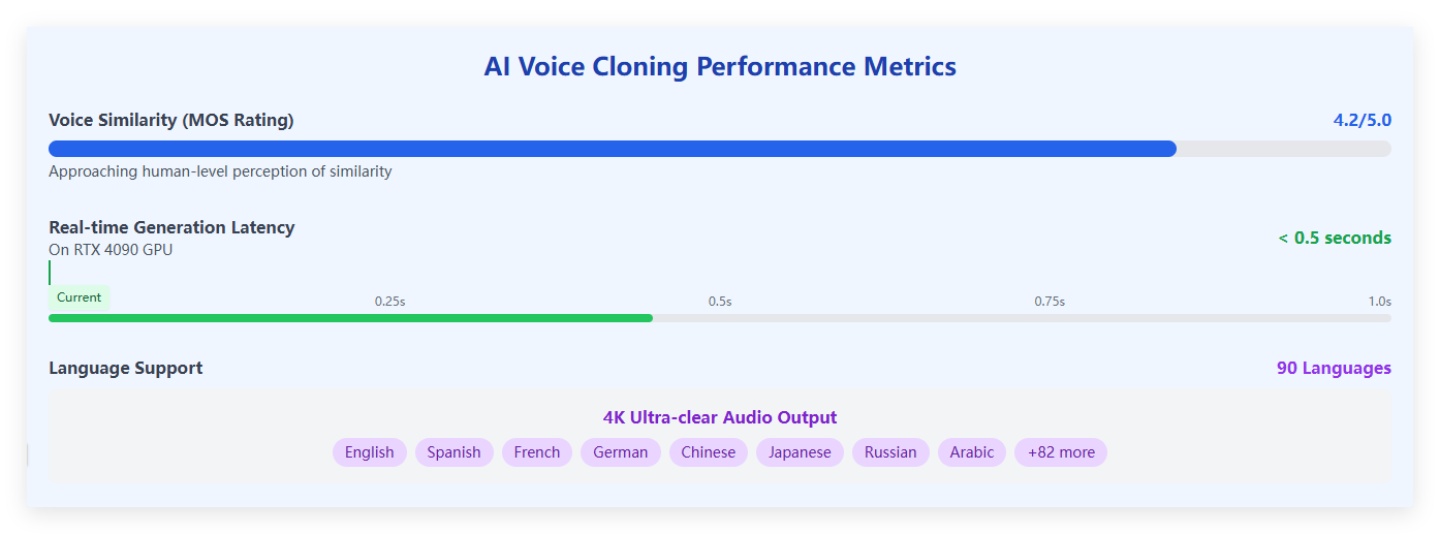
Performance Metrics That Demonstrate Today's Capabilities
To understand just how far AI voice cloning has come, consider these concrete performance parameters:
- Voice similarity achieves Mean Opinion Score (MOS) ratings of 4.2 out of 5, approaching human-level perception of similarity
- Real-time generation latency less than 0.5 seconds on high-end hardware (RTX 4090 GPU)
- Support for 4K ultra-clear audio output across 90 different languages
For example, Microsoft's VALL-E can generate personalized speech from just 3 seconds of audio, while Resemble AI requires only 30 seconds of sample audio to create clones capable of real-time modifications to pitch, speed, and emotional tone. ElevenLabs offers adjustable parameters for voice stability, clarity, and stylistic exaggeration, giving users unprecedented control over the output.
How Does AI Voice Cloning Surpass Human Capabilities?
AI voice cloning technology excels beyond human capabilities in several key dimensions, offering advantages that make it increasingly attractive for various applications. The efficiency and scale advantages are particularly striking: AI can generate high-quality voice content in minutes, dramatically outpacing human recording processes in terms of both time and cost. This efficiency makes instant AI voice cloning especially valuable for bulk content production and multilingual versions.
The cost and time savings are substantial. For instance, AI dubbing in applications like CapCut (formerly TikTok's editing tool Jianying) has reduced voice-over production time from 3 hours to just 3 minutes, with costs at merely 0.003 times that of human voice actors. Similarly, companies like HeyGen have used their Voice Engine to translate videos into 16 different languages, resulting in a 400% increase in user coverage.
Personalization and Flexibility Advantages
The flexibility of AI voice cloning offers another significant advantage. These systems can quickly generate multiple variations in emotion, speed, and accent from minimal samples—a versatility that human voice actors would struggle to match efficiently. Some advanced platforms like Noiz AI TTS can even simulate subtle vocal nuances such as sighs and pauses, approaching the quality of professional voice actors.
AI voice cloning also provides unmatched consistency and automation potential, ensuring uniform voice styling across diverse applications including customer service, virtual assistants, and gaming characters. To maximize these benefits, many productions now employ a hybrid approach, using AI automation for repetitive tasks while preserving human oversight for creative and emotional elements that benefit from a human touch.
The Limitations of AI Voice Cloning
Despite impressive advancements, AI voice cloning still faces significant limitations that require human intervention in certain scenarios. Complex emotional expression, natural fluency in long-form narratives, and subtle voice details often necessitate human adjustments to achieve optimal results. Understanding these constraints is essential for realistic implementation of the technology.
Several factors contribute to these limitations. Current models demonstrate restricted semantic understanding and contextual coherence, training data still lacks sufficient diversity, and generated speech occasionally produces unnatural pauses or pronunciation errors. These challenges highlight areas where human expertise remains valuable in the voice production pipeline.
1. Technical Improvement Trajectories
Future technical improvements will need to focus on several key directions:
- Enhanced multimodal semantic understanding
- More sophisticated emotional modeling
- Improved real-time interaction capabilities
- Development of greener computing approaches
These advancements would help address current shortcomings in naturalness and versatility.
2. Ethical and Security Concerns
Perhaps most concerning are the ethical and security implications of AI voice cloning. The technology can be easily misused for fraud, evidence fabrication, and other malicious purposes, creating serious privacy and copyright issues that urgently require legal frameworks and technical safeguards. In a striking example, a finance worker transferred $25 million after a video call with a deepfake 'chief financial officer.'
Despite these challenges, AI voice cloning is poised to deeply integrate with virtual assistants, entertainment, education, and other sectors, becoming an integral component of digital human interaction. The industry must balance innovation with ethical risk management, potentially through approaches like "chain of thought" (CoT) modeling to improve emotional control precision.
What Are the FAQs About AI Voice Cloning?
Q: What is AI voice cloning?
A: AI voice cloning is a technology that uses deep learning models (such as acoustic feature extraction networks and generative networks) to replicate the voice characteristics of a target speaker. By training on recordings of the target voice source, the model can generate new speech that closely resembles the original in timbre, pace, intonation, and other qualities.
Q: How does AI voice cloning work?
A: The core process typically includes three main steps: voice capture and feature extraction (analyzing the input voice to extract acoustic features like Mel-frequency cepstral coefficients), model training (feeding these features into encoder-decoder architectures such as Tacotron, Transformer, or VAE), and synthesis with post-processing (generating new spectrograms and converting them into audible waveforms using neural vocoders like WaveNet or HiFi-GAN).
Q: Is AI voice cloning legal?
A: The legal status of voice cloning varies by country and is still evolving. The U.S. Federal Trade Commission (FTC) and some European countries take a strict stance against unauthorized replication of personal voices. Using AI voice cloning may involve rights of publicity, privacy rights, and copyright issues, so obtaining authorization or using clear "saturated authorization" agreements before cloning is recommended.
Q: Which is the best AI voice cloning tool?
A: Leading options include ElevenLabs, which can generate high-fidelity clones from just a few seconds of audio and supports 29 languages for applications like video dubbing, podcasts, and gaming. Another strong contender is PlayHT, offering an all-in-one AI voice studio with integrated cloning, text-to-speech, noise reduction, and enterprise-grade security certification.
Q: Is AI voice cloning free?
A: Some platforms like Speechify and Vocloner offer free trial experiences that allow cloning short segments (seconds to tens of seconds) in a browser with daily usage limits. Unlocking higher call volumes and full features typically requires subscribing to paid plans.
Q: Can voice cloning work with just a few seconds of audio?
A: Yes, mainstream platforms like ElevenLabs and Speechify claim that 3-30 seconds of sample recordings can produce "nearly indistinguishable" high-fidelity clones. Some platforms even offer thousands of free clone characters daily.

Conclusion: Balancing Innovation with Responsibility in Voice Cloning
The rapid evolution of instant AI voice cloning from its rudimentary beginnings to today's sophisticated systems represents one of the most fascinating technological journeys in artificial intelligence. What began as mechanical, rule-based speech synthesis has transformed into neural network-powered voice replication that can convincingly mimic human voices from minimal input data.
As we've explored, the current state of AI voice cloning offers remarkable capabilities—high-fidelity reproduction, minimal training requirements, emotional range, and multilingual support—that were unimaginable just a decade ago. These advancements have opened doors to unprecedented applications in entertainment, accessibility, education, and business communication.
However, this powerful technology brings with it a responsibility to address critical challenges. The ethical implications of creating synthetic voices that can impersonate real individuals raise serious concerns about consent, identity theft, and misinformation. The technical limitations in semantic understanding and emotional nuance remind us that human oversight remains essential. Meanwhile, the environmental impact of training increasingly complex models demands attention to sustainable AI development practices.
The future of instant AI voice cloning will likely be shaped by how well we balance innovation with ethical guardrails. Can we develop robust verification mechanisms to authenticate real voices? Will legal frameworks evolve quickly enough to address voice rights and ownership? How can we ensure equitable access to this technology while preventing malicious exploitation?
As AI voice cloning continues to advance, perhaps the most critical task ahead lies not in pushing technical boundaries further, but in cultivating a responsible ecosystem that maximizes benefits while minimizing harms. Only through thoughtful implementation and governance can we ensure that this powerful technology serves humanity's best interests rather than becoming a tool for deception and manipulation.
 Submit Your AI Tool For FREE!Showcase Your Innovation To Thousands Of AI Enthusiasts!
Submit Your AI Tool For FREE!Showcase Your Innovation To Thousands Of AI Enthusiasts!

No comments yet. Be the first to comment!